
Kaldi
How does it work?
 1Download and run the debian package
1Download and run the debian package 2Upload video/speech files into the tool, using the instructions provided
2Upload video/speech files into the tool, using the instructions provided 3Edit the transcription, as required
3Edit the transcription, as required
What is Kaldi?

Kaldi is a speech recognition toolkit, built upon the open source software originally developed for use by speech recognition researchers. The quickest way to search through a piece of audio or video is via a transcript, but transcription by hand is a costly and time consuming endeavour. Kaldi has been designed as a means of automating the same process for free, requiring only a small amount of installation effort from a software developer. The Â鶹Éç-Kaldi component provides a machine learning model built using the tools in the Open Source Kaldi toolkit and audio / text data from Â鶹Éç programme and an easy to use interface that makes it simple to get up and running.
Top tips to get you ready

Transcription quality will depend on things like audio quality, accents, background noises, cross-talking etc - so transcribe clean audio where possible

If you record speech and atmospherics on separate channels, export the speech channel only
What have we learnt from Kaldi?
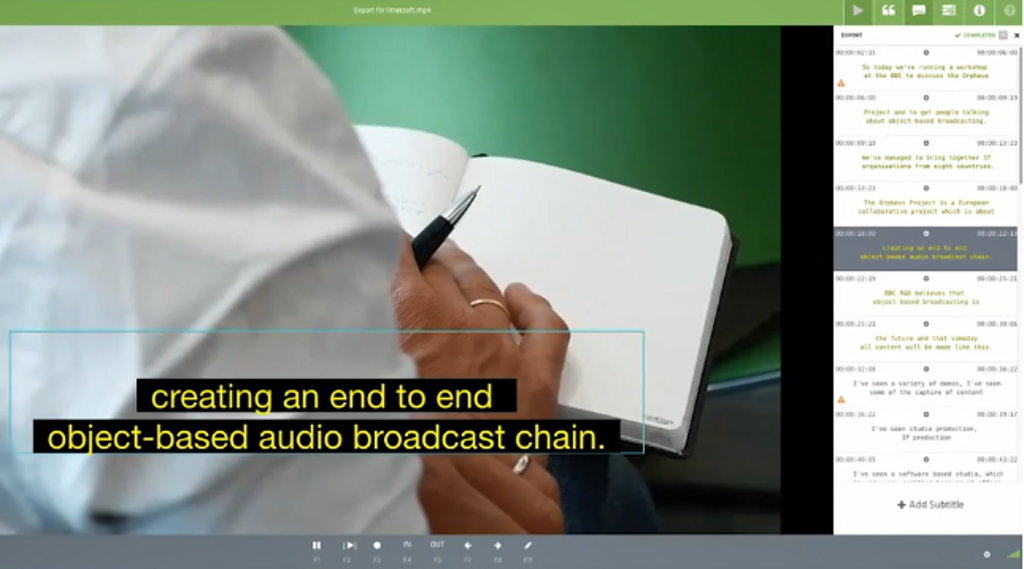
Kaldi has been used extensively within the Â鶹Éç, with a variety of learnings from each project. Â鶹Éç Newslabs' project showed that speech-to-text is a tremendous timesaver for journalists who need to be across a wide number of video feeds. Their project proved that creating subtitles for viral videoclips can be done much quicker than was previously imagined. Â鶹Éç Rewind also used speech-to-text to open up almost a million hours of material from the Â鶹Éç Archive.